Wordleが面白くて毎日やっています。
常々疑問なのが、どの単語を最初に入力すれば正解に近づくのか、ということです。
今回はその疑問を晴らすため、Pythonを使って調べていきたいと思います。
使用ライブラリ
pandas
seaborn
データセット
答えの単語リストはgithubで公開されています。
https://github.com/alex1770/wordle/blob/main/wordlist_hidden
メモ帳にコピペして、wordle.txtという名前で保存します。
考え方
Wordleでは入力した単語の位置が合っている時に緑、とりあえず含まれている時に黄色でヒントが出ます。
緑の場合と黄色の場合に分けて、カウントアップして評価する方法を取ります。
例えば推測値がCHILDで、答えがALIVEだとします。
この場合、Iで緑1ポイント、Lで黄色1ポイントという風なルールです。
これを総当たりで調べます。
計算してdfに保存
早速コードを書いていきます。
まずは上記の総当たり計算をして、CSV形式で保存するところまでです。
import pandas as pd
def word_list():
"""単語リストを返す"""
words = []
with open('wordle.txt', 'r') as f:
for word in f:
words.append(word.strip())
return words
def count(count_green, count_yellow, guess, answer):
"""推測と答えを比較してカウントアップ"""
# 検査済みの文字を保存
already_checked = []
# 一文字ずつ取り出す
for g, a in zip(guess, answer):
# 緑の判定
if g == a:
count_green += 1
continue
# 例えば、eerieなどの単語を検査する際に、eで何回もカウントアップされたくない
# そのため、検査済みの場合は飛ばす
if g in already_checked:
continue
# 黄色の判定
if g in answer:
count_yellow += 1
already_checked.append(g)
return count_green, count_yellow
def check_duplicate(guess):
"""重複した単語が含まれていたら1を返す"""
flag_duplicate = 0
for char in guess:
if guess.count(char) > 1:
flag_duplicate = 1
break
return flag_duplicate
def create_result_df():
"""調べた結果をdfにして保存"""
# 単語リストを生成
words = word_list()
# 総当たりで調べる
results = []
for guess in words:
count_green = 0 # 緑が出た回数
count_yellow = 0 # 黄色が出た回数
for answer in words:
# 推測と答えが一致している場合はスキップ
if guess == answer:
continue
# カウントアップ
count_green, count_yellow = count(count_green, count_yellow, guess, answer)
# 同じ文字が使われているかどうか調べる
flag_duplicate = check_duplicate(guess)
# 結果リストに追加
results.append([guess, count_green, count_yellow, flag_duplicate])
# 結果をpandas DataFrameに保存
columns = ['word', 'count_green', 'count_yellow', 'flag_duplicate']
df = pd.DataFrame(results, columns=columns)
df.to_csv('results.csv', index=False)
評価の肝になるのが、count関数ですね。
推測値と答えを一文字ずつぶつけていって、条件に一致した時にカウントアップさせます。
緑と黄色で二重評価が起きないように、緑の判定が出たらループを抜けるようにしています。
それと、重複した単語がある場合は、flag_duplicateに1を入れるようにしています。
例えばBELLYはLが重複しているので1です。
これはのちに重複の有無で比較をするために加えています。
実行すると、同ディレクトリにCSV形式で保存されます。
回数ランキング
次にこのCSVをソートして簡単なランキングを表示させていきます。
まずはデータをプリントしてみましょう。
def job():
df = pd.read_csv('results.csv')
print(df)
if __name__ == '__main__':
# 作成が終わったのでコメントアウト
# create_result_df()
job()
word count_green count_yellow flag_duplicate
0 aback 724 1527 1
1 abase 1054 2221 1
2 abate 1022 2302 1
3 abbey 891 1824 1
4 abbot 594 1988 1
... ... ... ... ...
2310 young 668 1724 0
2311 youth 723 1865 0
2312 zebra 513 2586 0
2313 zesty 823 1965 0
2314 zonal 735 2075 0
[2315 rows x 4 columns]
このように各単語ごとに緑の回数、黄色の回数、重複フラグが書きこまれています。
緑の回数が多い単語
とりあえず5単語のみ表示させます。
ascending=Falseとすると降順で並び替えされます。
df = df.sort_values('count_green', ascending=False) word count_green count_yellow flag_duplicate
1777 slate 1432 2461 0
1648 sauce 1406 2077 0
1783 slice 1404 2008 0
1704 shale 1398 2207 0
1651 saute 1393 2309 0
緑の回数が少ない単語
df = df.sort_values('count_green', ascending=True)
word count_green count_yellow flag_duplicate
1320 nymph 305 1680 0
1029 inbox 313 1856 0
677 ethos 321 3067 0
28 affix 335 1490 1
2150 umbra 339 2424 0
想像はしていましたが、こちらはマニアックっぽい単語が多いです。
黄色の回数が多い単語
df = df.sort_values('count_yellow', ascending=False)
word count_green count_yellow flag_duplicate
1339 opera 490 3326 0
1572 renal 800 3195 0
48 alert 919 3193 0
67 alter 978 3134 0
692 extra 408 3093 0
ALERTとALTERは使われている文字は同じですが、ALTERを入力した方が緑を獲得できる可能性が高いです。
黄色の回数が少ない単語
df = df.sort_values('count_yellow', ascending=True)
word count_green count_yellow flag_duplicate
830 fuzzy 712 425 1
745 fizzy 728 599 1
1275 mummy 781 619 1
1496 puppy 795 668 1
1050 jazzy 714 695 1
このケースは重複した文字が使われている単語の成績が悪いです。
重複を取り除くと以下のようになります。
df = df[df['flag_duplicate'] == 0]
df = df.sort_values('count_yellow', ascending=True) word count_green count_yellow flag_duplicate
1065 jumpy 676 864 0
825 funky 875 953 0
1063 juicy 983 1008 0
1518 quick 735 1043 0
1489 pudgy 838 1047 0
可視化
次にこのデータを可視化して分布をみていきましょう。
violinplotとscatterplotの二種類で確認します。
Violin Plot
import matplotlib.pyplot as plt # 追加
import seaborn as sns # 追加
def violin_plot_green(df):
p = sns.violinplot(data=df, x='flag_duplicate', y="count_green",
split=True, inner="quart", linewidth=1)
sns.despine(left=True)
p.set_title('Violin Count Green')
plt.show()
def violin_plot_yellow(df):
p = sns.violinplot(data=df, x='flag_duplicate', y="count_yellow",
split=True, inner="quart", linewidth=1)
sns.despine(left=True)
p.set_title('Violin Count Yellow')
plt.show()
def job():
df = pd.read_csv('results.csv')
violin_plot_green(df)
violin_plot_yellow(df)
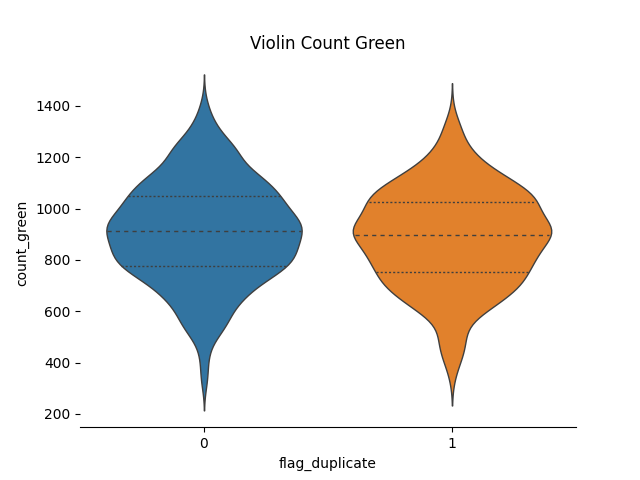
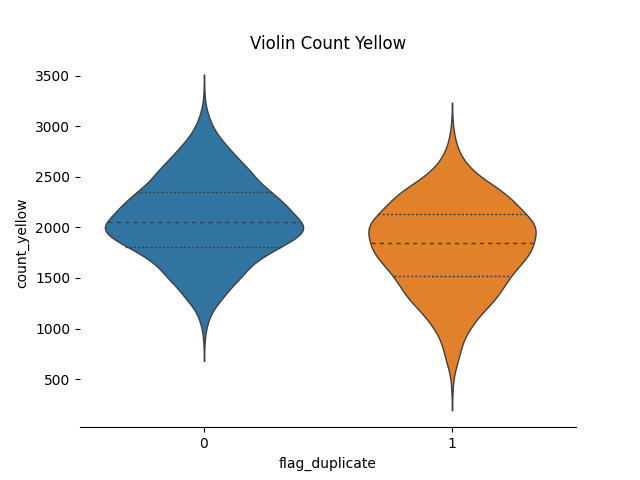
当然かもしれませんが、重複文字の有無は緑の出る回数には影響はしません。
黄色の分布には違いがあるように見えます。
Scatter Plot
violinプロットは緑と黄色を個別にみる時に適しています。
全体的なばらつきを見る際はscatter plotにするとわかりやすいです。
def scatter_plot(df):
f, ax = plt.subplots(figsize=(6.5, 6.5))
sns.despine(f, left=True, bottom=True)
sns.scatterplot(x='count_green', y='count_yellow',
hue="flag_duplicate",
palette="ch:r=-.2,d=.3_r",
sizes=(1, 8), linewidth=0,
data=df, ax=ax)
plt.show()
def job():
df = pd.read_csv('results.csv')
scatter_plot(df)
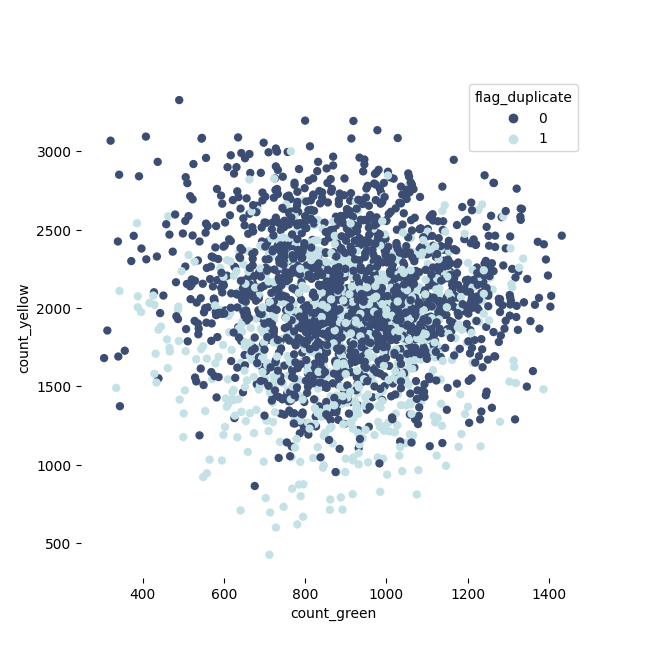
できるだけ、右上に属しているのが打率が高いと言えそうです。
各ポイントに文字を付けて確認してみましょう。
全てにつけると見づらいので、緑が1000以上、黄色が2000以上で足切りします。
def scatter_plot_with_word(df):
# 足切り
df = df[df['count_yellow'] >= 2000]
df = df[df['count_green'] >= 1000]
f, ax = plt.subplots(figsize=(6.5, 6.5))
sns.despine(f, left=True, bottom=True)
sns.scatterplot(x='count_green', y='count_yellow',
hue="flag_duplicate",
palette="ch:r=-.2,d=.3_r",
sizes=(1, 8), linewidth=0,
data=df, ax=ax)
# 文字を付ける
for val in df[['word', 'count_green', 'count_yellow']].values:
word = val[0]
x_pos = val[1]
y_pos = val[2]
ax.text(x_pos + 2, y_pos + 2, word)
plt.show()
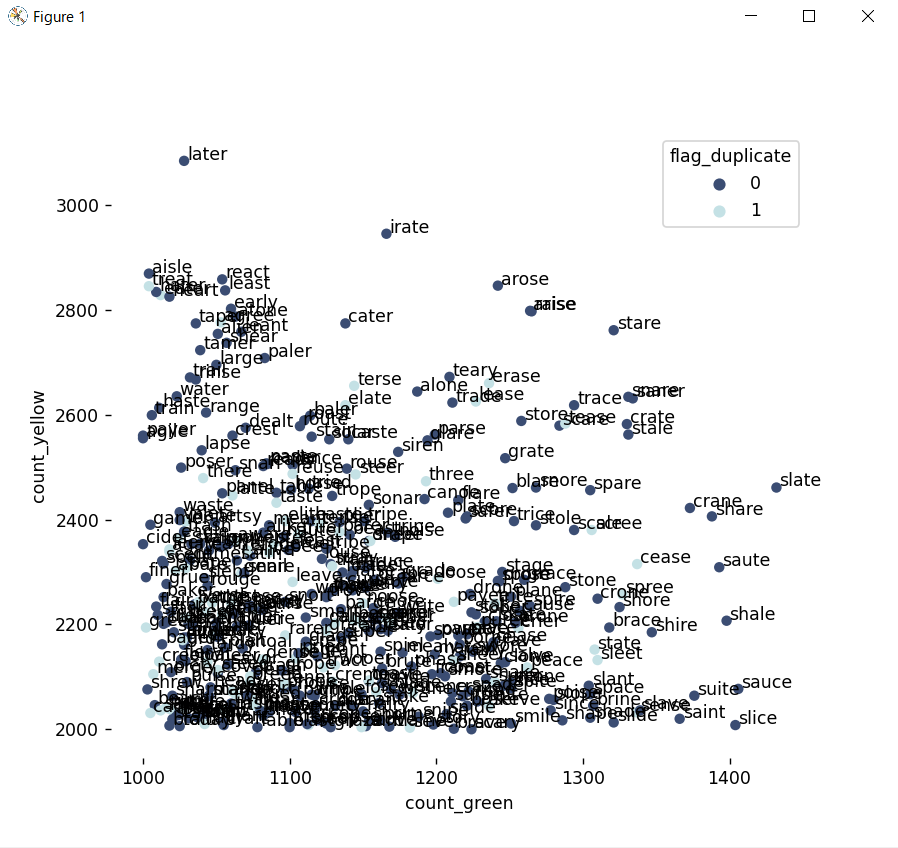
このように表示がされます。
まとめ
今回は総当たり式で緑と黄色の回数を数えてみました。
この方法だと、これだ!という一つの単語にたどり着くのは難しそうです。
しかし、少なくとも次のことが分かりました。
まず、一番緑のヒントを期待できるのはSLATE、黄色はOPERAですね。
ただし、OPERAは緑の期待値が低いため一発目に入力するのは避けた方がいいかもしれません。
散布図を見てみますと、このあたりの単語のパフォーマンスが高いです。
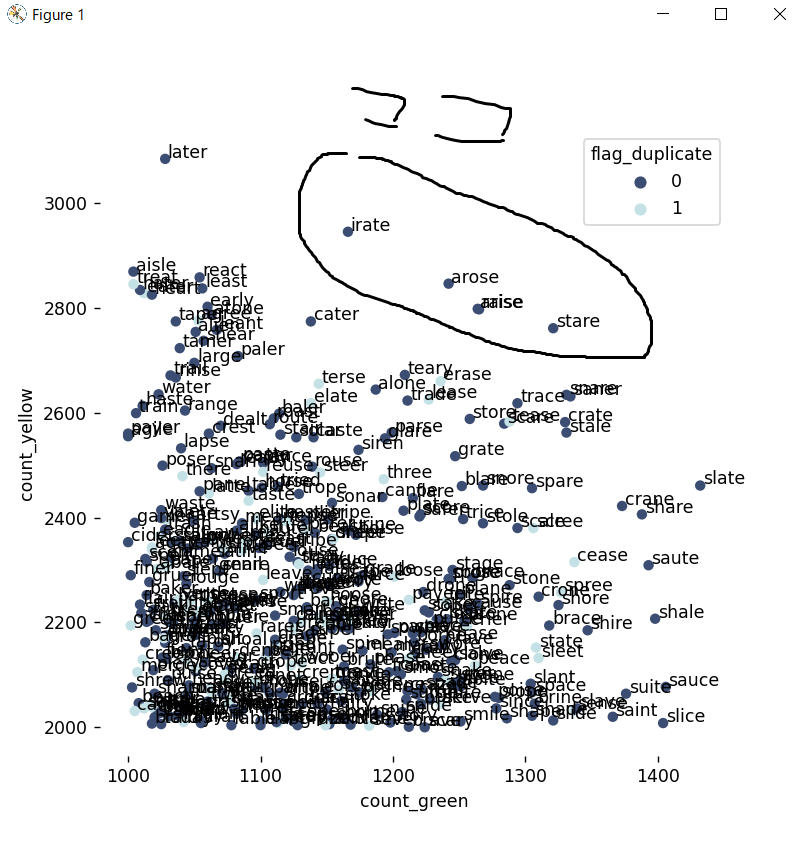
書き出しますとこの5単語です。
- STARE
- ARISE
- RAISE
- AROSE
- IRATE
今回はどの単語がヒントを獲得できる可能性が高いか、という観点から調べてみました。
次のWordleで試すのが楽しみです。
ソースコード
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
def word_list():
"""単語リストを返す"""
words = []
with open('wordle.txt', 'r') as f:
for word in f:
words.append(word.strip())
return words
def count(count_green, count_yellow, guess, answer):
"""推測と答えを比較してカウントアップ"""
# 検査済みの文字を保存
already_checked = []
# 一文字ずつ取り出す
for g, a in zip(guess, answer):
# 緑の判定
if g == a:
count_green += 1
continue
# 例えば、eerieなどの単語を検査する際に、eで何回もカウントアップされたくない
# そのため、検査済みの場合は飛ばす
if g in already_checked:
continue
# 黄色の判定
if g in answer:
count_yellow += 1
already_checked.append(g)
return count_green, count_yellow
def check_duplicate(guess):
"""重複した単語が含まれていたら1を返す"""
flag_duplicate = 0
for char in guess:
if guess.count(char) > 1:
flag_duplicate = 1
break
return flag_duplicate
def create_result_df():
"""調べた結果をdfにして保存"""
# 単語リストを生成
words = word_list()
# 総当たりで調べる
results = []
for guess in words:
count_green = 0 # 緑が出た回数
count_yellow = 0 # 黄色が出た回数
for answer in words:
# 推測と答えが一致している場合はスキップ
if guess == answer:
continue
# カウントアップ
count_green, count_yellow = count(count_green, count_yellow, guess, answer)
# 同じ文字が使われているかどうか調べる
flag_duplicate = check_duplicate(guess)
# 結果リストに追加
results.append([guess, count_green, count_yellow, flag_duplicate])
# 結果をpandas DataFrameに保存
columns = ['word', 'count_green', 'count_yellow', 'flag_duplicate']
df = pd.DataFrame(results, columns=columns)
df.to_csv('results.csv', index=False)
def violin_plot_green(df):
"""緑カウントのバイオリンプロットを表示"""
p = sns.violinplot(data=df, x='flag_duplicate', y="count_green",
split=True, inner="quart", linewidth=1)
sns.despine(left=True)
p.set_title('Violin Count Green')
plt.show()
def violin_plot_yellow(df):
"""黄色カウントのバイオリンプロットを表示"""
p = sns.violinplot(data=df, x='flag_duplicate', y="count_yellow",
split=True, inner="quart", linewidth=1)
sns.despine(left=True)
p.set_title('Violin Count Yellow')
plt.show()
def scatter_plot(df):
"""散布図"""
f, ax = plt.subplots(figsize=(6.5, 6.5))
sns.despine(f, left=True, bottom=True)
sns.scatterplot(x='count_green', y='count_yellow',
hue="flag_duplicate",
palette="ch:r=-.2,d=.3_r",
sizes=(1, 8), linewidth=0,
data=df, ax=ax)
plt.show()
def scatter_plot_with_word(df):
"""文字を付きの散布図"""
# 足切り
df = df[df['count_yellow'] >= 2000]
df = df[df['count_green'] >= 1000]
f, ax = plt.subplots(figsize=(6.5, 6.5))
sns.despine(f, left=True, bottom=True)
sns.scatterplot(x='count_green', y='count_yellow',
palette="ch:r=-.2,d=.3_r",
sizes=(1, 8), linewidth=0,
data=df, ax=ax)
# 文字を付ける
for val in df[['word', 'count_green', 'count_yellow']].values:
word = val[0]
x_pos = val[1]
y_pos = val[2]
ax.text(x_pos + 2, y_pos + 2, word, )
plt.show() Share
Share