今回はPythonを使ってEdinetから四半期報告書を取得する方法についての記事です。
Edinetとは
金融庁が運営している有価証券報告書等の電子開示システムです。
https://disclosure.edinet-fsa.go.jp/EKW0EZ0001.html
上場企業から発表される有価証券報告書についてはこのシステムに登録されることになります。
この記事でやること
Edinetですが書類を取得するためのAPIが公開されています。
つまりプログラムを走らせれば書類のダウンロードが可能となります。
今回は四半期報告書をEdinetからダウンロードして、売上や純利益などの値を取得するプログラムを紹介します。
必要ライブラリ
pip install requests
pip install edinet-xbrlrequestsはAPIを叩くのに必要です。
edinet-xbrlはダウンロードした書類から値を取得するのに使います。
書類をダウンロードする
早速Edinetから書類をダウンロードするプログラムを書いていきましょう。
今回は題材として任天堂の四半期報告書を取得していきます。
書類ですが、endpointに提出書類の書類IDを付記してGETリクエストを送るとダウンロードできます。
そのため、前段として書類IDを特定する必要があります。
これを特定するためには日付を指定して提出された書類の一覧を確認するAPIを叩く必要があります。
提出された書類を確認する
日付を指定して以下のようにするとレスポンスが返ってきます。
任天堂の第三四半期報告書は2022年2月10日に提出されていますので、2022-02-10をパラメーターに渡してあげます。
import requests
def get_submission_docs(date):
"""提出された書類を把握するためのAPI"""
url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json'
params = {
"date": date,
"type": 2,
}
return requests.get(url, params=params, verify=False)
def job():
date = '2022-02-10'
res = get_submission_docs(date)
if __name__ == '__main__':
job()試しにresponseをprintしてみましょう。
from pprint import pprint
pprint(res.json()['metadata'])以下のようにprintされます。
{'message': 'OK',
'parameter': {'date': '2022-02-10', 'type': '2'},
'processDateTime': '2022-04-10 00:00',
'resultset': {'count': 2448},
'status': '200',
'title': '提出された書類を把握するためのAPI'}
2,448件提出されたみたいです。
書類の詳細情報はresultsキーを指定すると取得できます。
results = res.json()['results']
pprint(results[0])
以下のようにprintされます。
{'JCN': '3130001009314',
'attachDocFlag': '0',
'currentReportReason': None,
'disclosureStatus': '0',
'docDescription': '四半期報告書-第98期第3四半期(令和3年10月1日-令和3年12月31日)',
'docID': 'S100NEOG',
'docInfoEditStatus': '0',
'docTypeCode': '140',
'edinetCode': 'E00884',
'englishDocFlag': '0',
'filerName': '三洋化成工業株式会社',
'formCode': '043000',
'fundCode': None,
'issuerEdinetCode': None,
'opeDateTime': None,
'ordinanceCode': '010',
'parentDocID': None,
'pdfFlag': '1',
'periodEnd': '2021-12-31',
'periodStart': '2021-10-01',
'secCode': '44710',
'seqNumber': 1,
'subjectEdinetCode': None,
'submitDateTime': '2022-02-10 09:00',
'subsidiaryEdinetCode': None,
'withdrawalStatus': '0',
'xbrlFlag': '1'}
最初のデータは三洋化成工業さんでした。
いずれにせよ、ここからお目当ての任天堂のdocIDを取得する作業をしていくわけになります。
ここでdocTypeCodeとdocDescriptionに注目をしてみます。
{...
'docDescription': '四半期報告書-第98期第3四半期(令和3年10月1日-令和3年12月31日)',
...
'docTypeCode': '140',
...}
printしたのがたまたま四半期報告書でラッキーでした。
どうやら四半期報告書はdocTypeCodeが140で指定されているということが分かります。
docTypeCodeを一応確認しておく
ここは本編にあまり関係ないですが、一応docTypeCodeごとの書類を確認してみました。
def print_doc_type_dict(results):
"""
提出された書類のdoctypecodeを確認する関数
"""
dic = {}
for result in results:
key = result['docTypeCode']
value = result['docDescription']
dic.setdefault(key, value)
print(dic)
このようになります。
{'140': '四半期報告書-第98期第3四半期(令和3年10月1日-令和3年12月31日)',
'120': '有価証券報告書(内国投資信託受益証券)-第24期(令和3年5月11日-令和3年11月10日)',
'220': '自己株券買付状況報告書(法24条の6第1項に基づくもの)',
'160': '半期報告書(内国投資信託受益証券)-第4期(令和3年5月18日-令和4年5月16日)',
'135': '確認書',
'040': '訂正有価証券届出書(内国投資信託受益証券)',
'030': '有価証券届出書(内国投資信託受益証券)',
'180': '臨時報告書(内国特定有価証券)',
'090': '訂正発行登録書',
'350': '変更報告書',
'360': '訂正報告書(大量保有報告書・変更報告書)',
'100': '発行登録追補書類(株券、社債券等)', None: None,
'130': '訂正有価証券報告書-第79期(令和2年4月1日-令和3年3月31日)',
'080': '発行登録書(株券、社債券等)',
'240': '公開買付届出書', '150': '訂正四半期報告書-第52期第3四半期(令和3年10月1日-令和3年12月31日)',
'250': '訂正公開買付届出書',
'190': '訂正臨時報告書',
'290': '意見表明報告書'}
docIDを取得する
次に任天堂が提出した四半期報告書のdocIDを特定していきます。
resultsを順繰り探索していけばできそうです。
方法は色々あって、例えば任天堂という文字列でマッチをかけても良いと思いますが、確実にやるならEdinetが提供している会社一覧を当たるのがいいです。
下記ページからcsvデータがダウンロードできます。
このページの下の方にEdinetコードリストがあるのでクリックです。

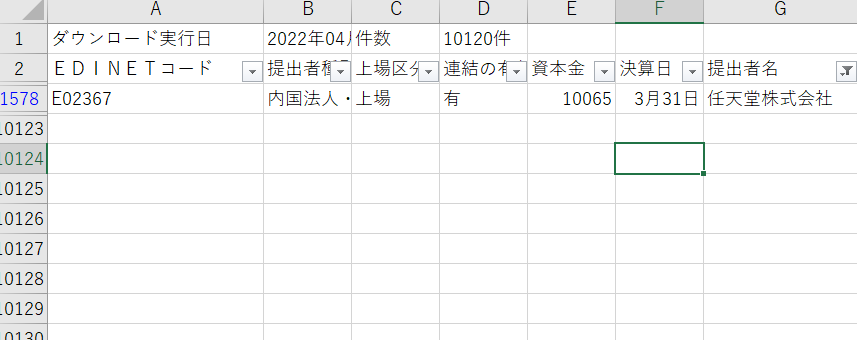
任天堂のEdinetコードがE02367であることが分かりました。
def get_doc_id(filer_code, results):
"""edinet codeを指定してresultからdocidを返す"""
doc_id = None
for result in results:
if result['docTypeCode'] != '140':
continue
if result['edinetCode'] == filer_code:
doc_id = result['docID']
return doc_id
def job():
date = '2022-02-10'
res = get_submission_docs(date)
results = res.json()['results']
edinet_code = 'E02367' # 任天堂
doc_id = get_doc_id(edinet_code, results)
print(doc_id)
以下のようにdocIDが出力されます。
S100NBQAdocIDを指定して書類をダウンロードする
これでダウンロードする準備が整いました。
以下のようなリクエストをするとバイナリデータが返ります。
def get_doc_binary_response(doc_id):
url = f'https://disclosure.edinet-fsa.go.jp/api/v1/documents/{doc_id}'
params = {
"type": 1
}
return requests.get(url, params=params, verify=False)
あとはこいつを書き出してやればいいわけです。
ここまでのソースコードの全文を載せます。
import requests
import zipfile # 追加
import os # 追加
from pathlib import Path # 追加
def get_submission_docs(date):
"""提出された書類を把握するためのAPI"""
url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json'
params = {
"date": date,
"type": 2,
}
return requests.get(url, params=params, verify=False)
def get_doc_id(filer_code, results):
"""edinet codeを指定してresultからdocidを返す"""
doc_id = None
for result in results:
if result['docTypeCode'] != '140':
continue
if result['edinetCode'] == filer_code:
doc_id = result['docID']
return doc_id
def get_doc_binary_response(doc_id):
url = f'https://disclosure.edinet-fsa.go.jp/api/v1/documents/{doc_id}'
params = {
"type": 1
}
return requests.get(url, params=params, verify=False)
def download_doc(date, edinet_code, binary_response):
# 保存用のreportフォルダを作る
base_dir = Path(__file__).resolve().parent
save_dir_name = 'quarterly_report'
if not os.path.exists(Path(base_dir, save_dir_name)):
os.makedirs(Path(base_dir, save_dir_name))
# 保存フォルダ名
folder_path = f'{base_dir}/{save_dir_name}/{date}_{edinet_code}'
# バイナリデータをzipに書き出す
with open(f'{folder_path}.zip', 'wb') as f:
for chunk in binary_response.iter_content(chunk_size=1024):
f.write(chunk)
# zipファイルを解凍する
with zipfile.ZipFile(f'{folder_path}.zip') as existing_zip:
existing_zip.extractall(folder_path)
def job():
date = '2022-02-10'
res = get_submission_docs(date)
results = res.json()['results']
edinet_code = 'E02367' # 任天堂
doc_id = get_doc_id(edinet_code, results)
doc_binary_response = get_doc_binary_response(doc_id)
download_doc(date, edinet_code, doc_binary_response)
if __name__ == '__main__':
job()
実行すると、以下のようにquarterly_report配下にデータが保存されます。
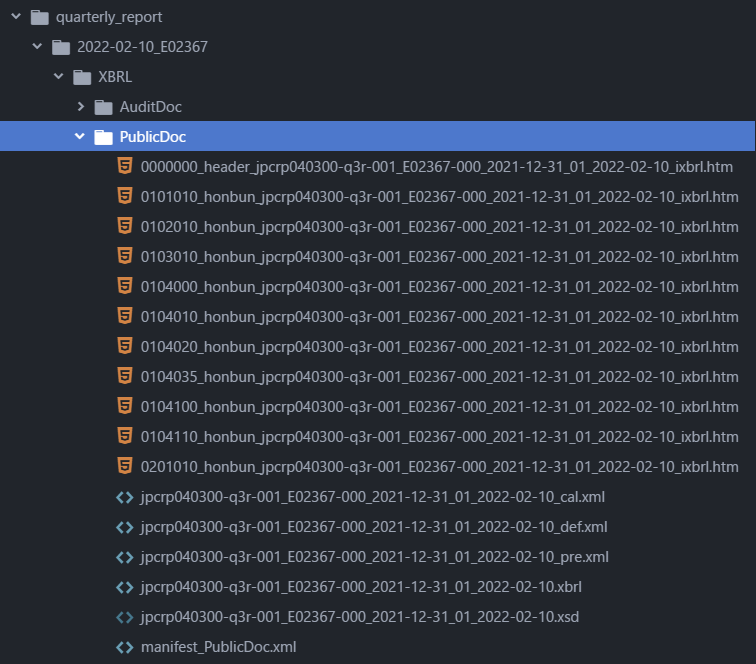
AuditDocは監査人のレビューなので今回は気にしません。
財務データが掲載されているのはPublicDocディレクトリの方です。
試しにhtmファイルをいくつか開いてみましょう。
以下のように四半期報告書がブラウザで表示されます。
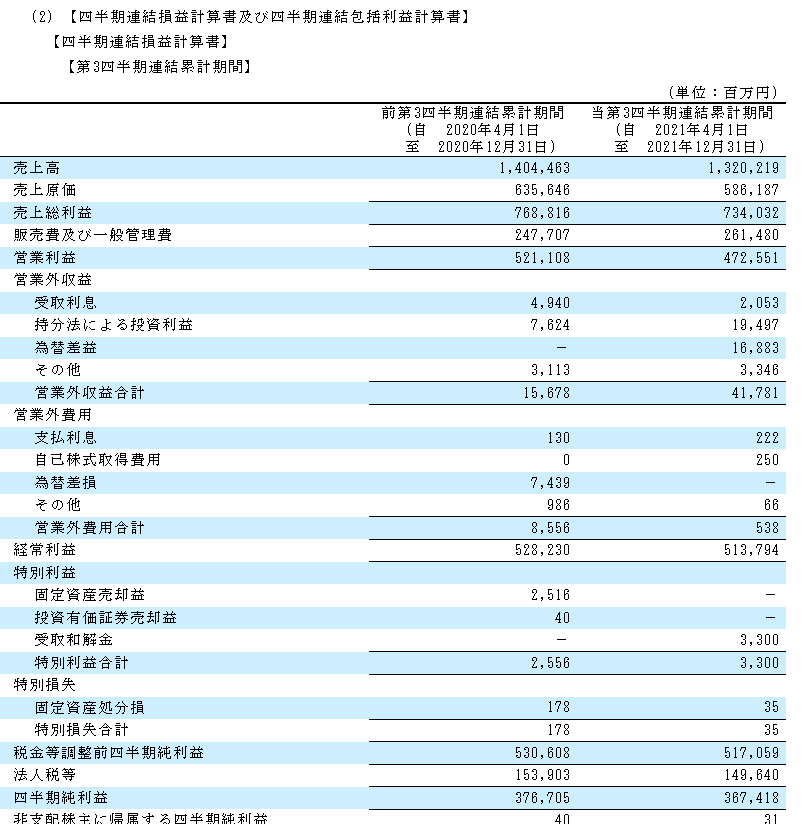
Edinetに提出されたデータはxmlをベースにしたxbrl形式で保存されています。
拡張子.xbrlのファイルがダウンロードされているはずです。
データを解析する
長くなりましたがここで、冒頭に紹介したedinet-xbrlライブラリを使っていくことになります。
前準備としてxbrlファイルのパスを探索する関数を書いておきましょう。
...
def generate_xbrl_file_path():
"""保存フォルダのxbrlファイルのパスをyieldして返す"""
# reportが保存してあるフォルダ
base_dir = Path(__file__).resolve().parent
save_dir_name = 'quarterly_report'
path = Path(base_dir, save_dir_name)
list_dir = os.listdir(path)
for root in list_dir:
for folder, sub_folders, files in os.walk(Path(path, root)):
# 監査人のフォルダは無視
if 'AuditDoc' in folder:
continue
if not files:
continue
for file in files:
extension = os.path.splitext(file)
if extension[1] == '.xbrl':
yield Path(path, folder, file)
def job():
date = '2022-02-10'
res = get_submission_docs(date)
results = res.json()['results']
edinet_code = 'E02367' # 任天堂
doc_id = get_doc_id(edinet_code, results)
doc_binary_response = get_doc_binary_response(doc_id)
download_doc(date, edinet_code, doc_binary_response)
for xbrl_file in generate_xbrl_file_path():
print(xbrl_file)
以下のようにxbrlファイルパスが返ります。
C:\Users\....\quarterly_report\2022-02-10_E02367\XBRL\PublicDoc\jpcrp040300-q3r-001_E02367-000_2021-12-31_01_2022-02-10.xbrl
後はedinet-xbrlを使って値を抜き出していきます。
https://github.com/BuffetCode/edinet_xbrl
こちらですがタクソノミのキーとcontext refを与えると値が抜き出せます。
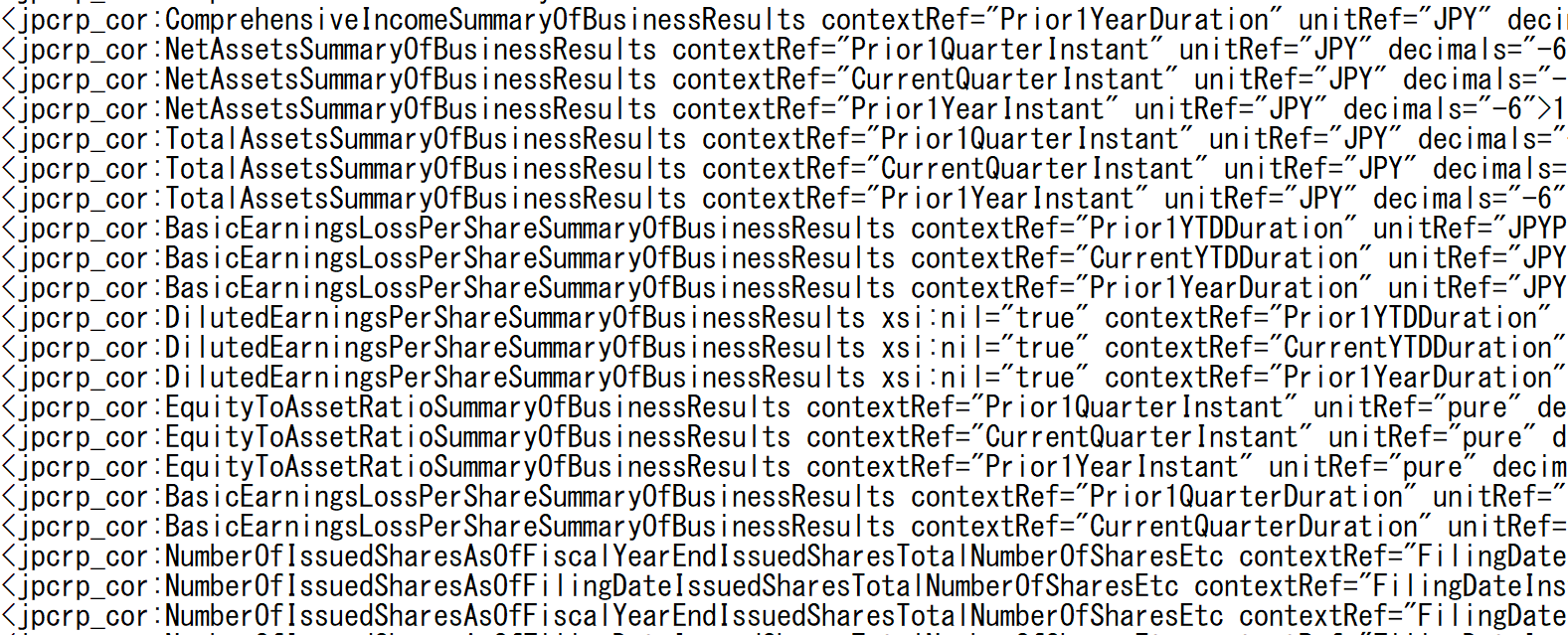
例えば売上高はxbrlファイルの中で以下のように表現されています。
<jppfs_cor:NetSales contextRef="CurrentYTDDuration" unitRef="JPY" decimals="-6">1320219000000</jppfs_cor:NetSales>
jppfs_cor:NetSalesがキーとなります。
そのまま以下のように指定します。
context_ref = 'CurrentYTDDuration'
# 売上高
key = 'jppfs_cor:NetSales'
sales = xbrl_object.get_data_by_context_ref(key, context_ref).get_value()
print(sales)
>>>
1320219000000
同様に指定していくと、当期純利益なんかも取り出せます。
# 四半期純利益
key='jppfs_cor:ProfitLoss'
net_income=xbrl_object.get_data_by_context_ref(key, context_ref).get_value()
print(net_income)
>>>
367418000000
タクソノミのキーについて
これが結構厄介で、任天堂は売上がNetSalesで表現されていましたが、企業や業種業態によって表現の仕方が違います。
一応キーのリストは下記に公開されていますが、あまり見る気になりませんでした。
https://www.fsa.go.jp/search/20211109.html
恐らくですが色んな企業の財務諸表とxbrlファイルをにらめっこして地道につぶしていくのが早いのかもしれません。
例えば売上高ですが、私が把握しているだけでも下記のような表現形態があるようです。
{
# 売上
'sales': [
'NetSales',
'NetSalesIFRS',
'GrossSales',
'OperatingRevenue',
'OperatingRevenue1',
'OperatingRevenue2',
'OperatingRevenuesRevOA',
'OperatingRevenueIFRS',
'OperatingIncomeINS',
'NetSalesOfCompletedConstructionContractsCNS',
'NetSalesAndOperatingRevenueIFRS',
'Revenue',
'RevenueIFRS',
'Revenue2IFRS',
'BusinessRevenue',
'TotalNetRevenuesIFRS',
'OrdinaryIncomeBNK',
'OperatingRevenueSEC',
'OperatingRevenueOILTelecommunications',
'RevenueRevOA',
'OperatingRevenueSPF',
'ShippingBusinessRevenueWAT',
'OperatingRevenueELE',
'RevenuesUSGAAPSummaryOfBusinessResults',
'TotalOperatingRevenue',
],...}
全ての書類をダウンロードする場合
今回は簡単にまとめると以下のような流れで処理を行いました。
- 日付を指定して提出された書類一覧を取得
- 任天堂の四半期報告書を特定してダウンロード
- xbrlファイルをパースして値を取得
任天堂の四半期報告書のみを題材にしましたが、以下のようにすれば、すべての書類を取得することができます。
例えば2022-02-10に提出されたすべての四半期報告書をダウンロードするには以下のようにします。
import time
import requests
import zipfile
import os
from pathlib import Path
def get_submission_docs(date):
"""提出された書類を把握するためのAPI"""
url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json'
params = {
"date": date,
"type": 2,
}
return requests.get(url, params=params, verify=False)
def generate_doc_information(results):
"""edinetCodeとdocIDをyieldして返す"""
for result in results:
if result['docTypeCode'] != '140':
continue
yield result['edinetCode'], result['docID']
def get_doc_binary_response(doc_id):
url = f'https://disclosure.edinet-fsa.go.jp/api/v1/documents/{doc_id}'
params = {
"type": 1
}
return requests.get(url, params=params, verify=False)
def download_doc(date, edinet_code, binary_response):
# 保存用のreportフォルダを作る
base_dir = Path(__file__).resolve().parent
save_dir_name = 'quarterly_report'
if not os.path.exists(Path(base_dir, save_dir_name)):
os.makedirs(Path(base_dir, save_dir_name))
# 保存フォルダ名
folder_path = f'{base_dir}/{save_dir_name}/{date}_{edinet_code}'
# バイナリデータをzipに書き出す
with open(f'{folder_path}.zip', 'wb') as f:
for chunk in binary_response.iter_content(chunk_size=1024):
f.write(chunk)
# zipファイルを解凍する
with zipfile.ZipFile(f'{folder_path}.zip') as existing_zip:
existing_zip.extractall(folder_path)
def job():
date = '2022-02-10'
res = get_submission_docs(date)
results = res.json()['results']
for edinet_code, doc_id in generate_doc_information(results):
binary = get_doc_binary_response(doc_id)
download_doc(date, edinet_code, binary)
time.sleep(.5)
if __name__ == '__main__':
job()
場合によっては以下のようなWarningが出るかもしれません。
InsecureRequestWarning: Unverified HTTPS request is being made to host 'disclosure.edinet-fsa.go.jp'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
以下のように冒頭に追加すると警告が出なくなります。
import time
import requests
import zipfile
import os
from pathlib import Path
# 追加
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
... Share
Share