今回は小ネタで、Pythonで数列の上昇基調と下降基調の転換点を見つける問題についてです。
[1,3,5,3,1,3]例えばこんな配列があったとします。
非常に雑な図ですが、折れ線グラフを書いてみました。
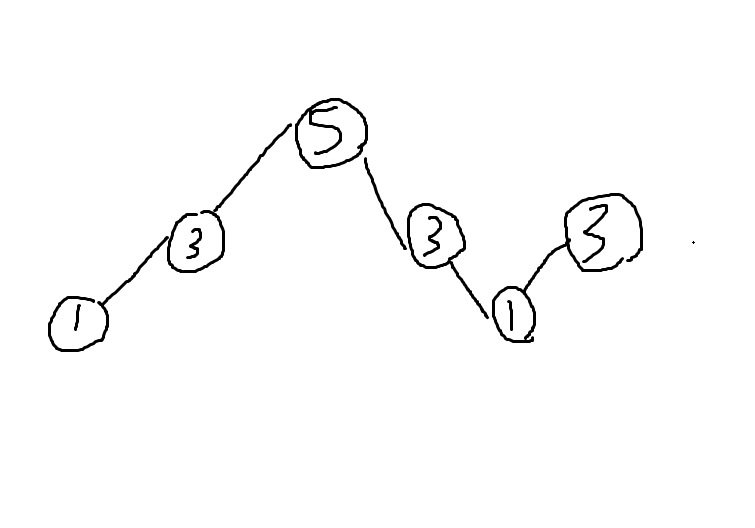
ここで、天井と底を見つけることを考えます。
3番目の5と、5番目の1が該当します。
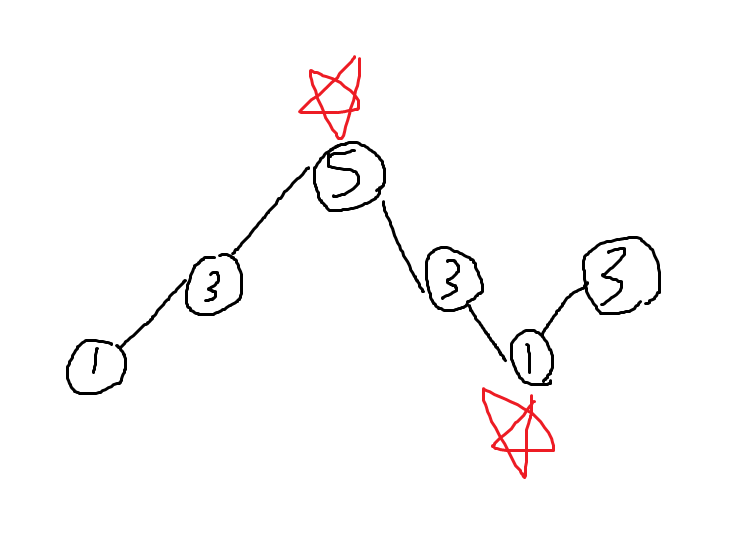
これを判定する、というようなプログラムを考えていきます。
[0, 0, 1, 0, 1, 0]
このように該当する日に1をつけることをゴールとします。
リストの繰り返しで実装
素朴に実装すると以下のようになります。
def main():
a_list = [1, 3, 5, 3, 1, 3]
length = len(a_list)
# 上げ基調かどうか
flg_up_trend = True
# 転換点に1をマークする
answer = [0] * length
for i in range(length - 1):
now = a_list[i]
nxt = a_list[i + 1]
# 次の方が大きい
if nxt >= now:
# いまが下げ基調の場合転換している
if not flg_up_trend:
answer[i] = 1
flg_up_trend = True
else:
# 次の方が小さく今が上げ基調の場合、転換している
if flg_up_trend:
answer[i] = 1
flg_up_trend = False
print(answer)
if __name__ == '__main__':
main()
[0, 0, 1, 0, 1, 0]まず上昇基調かどうかを示すflg_up_trendをTrueで始めます。
そうして今の数字と次の数字を見ていって、転換点を探します。
具体的には以下の条件で判定をしました。
次の数字の方が大きい場合:
もし下降基調だったら転換が起きています。
次の数字の方が小さい場合:
もし上昇基調だったら転換が起きています。
フラグと上げ・下げを二つ管理する必要があるので、混乱する気がします。
ランレングス圧縮で判定する
別のやり方としてランレングス圧縮表現を活用すると、少し見通しがよくなります。
ランレングス圧縮とは、例えばaaabbaaみたいな文字があったときに以下のように表現する手法です。
[(a,3),(b,2),(a,2)]これはitertoolsのgroupbyを使って以下のような関数で実装できます。
from itertools import groupby
def run_length_encode(s: str) -> list:
"""
RUN LENGTH ENCODING str -> list(tuple(str,int))
example) "aabbbbaaca" -> [('a', 2), ('b', 4), ('a', 2), ('c', 1), ('a', 1)]
"""
grouped = groupby(s)
ret = []
for k, v in grouped:
elm = (k, len(list(v)))
ret.append(elm)
return ret
こいつを活用してみることを考えます。
[1,3,5,3,1,3]もとの数列はこうでした。
まず、上昇を示すUと下降を示すDに変換します。
UUUDDUこれをランレングス圧縮します。
[(U,3),(D,2),(U,1)]こうなります。
あとは最初の3番目のインデックスと3+2の5番目のインデックスが転換点ということになります。
from itertools import groupby
def run_length_encode(s: str) -> list:
"""
RUN LENGTH ENCODING str -> list(tuple(str,int))
example) "aabbbbaaca" -> [('a', 2), ('b', 4), ('a', 2), ('c', 1), ('a', 1)]
"""
grouped = groupby(s)
ret = []
for k, v in grouped:
elm = (k, len(list(v)))
ret.append(elm)
return ret
def main():
a_list = [1, 3, 5, 3, 1, 3]
length = len(a_list)
# U,Dの文字に変換する
trend = ['U']
for i in range(1, length):
now = a_list[i]
prev = a_list[i - 1]
if now >= prev:
trend.append('U')
else:
trend.append('D')
trend_char = ''.join(trend)
# ランレングス圧縮する
rle = run_length_encode(trend_char)
answer = [0] * length
# インデックスの管理
idx = 0
for i in range(len(rle) - 1):
char, cnt = rle[i]
# 続いている個数を足す
idx += cnt
# 0インデックスのためマイナス1
answer[idx - 1] = 1
print(answer)
if __name__ == '__main__':
main()
[0, 0, 1, 0, 1, 0]手順をまとめると下記の3ステップとなります。
- 今の数字と前の数字を比較してUDの文字に変換する
- ランレングス圧縮する
- 繰り返して記録
計算量と作業は増えるのですが、シンプルに考えられる点にメリットがあります。
競プロなどでの活用
とまぁ色々と書きましたが、この記事を書いたきっかけは競プロでこの手の問題に出くわしたことがあるからです。
最初に所持金を1000円持っていて、株の値段の配列が与えられます。
最適な売買をして最大化した所持金を出力する、という問題です。
これは株をやったことがある人ならピンとくると思います。
折れ線の底値で買って、最高値で売る、を繰り返すのが最適です。
この記事で紹介した方法を使って解くことができます。
from itertools import groupby
def run_length_encode(s: str) -> list:
"""
RUN LENGTH ENCODING str -> list(tuple(str,int))
example) "aabbbbaaca" -> [('a', 2), ('b', 4), ('a', 2), ('c', 1), ('a', 1)]
"""
grouped = groupby(s)
ret = []
for k, v in grouped:
elm = (k, len(list(v)))
ret.append(elm)
return ret
def job():
n = int(input())
al = list(map(int, input().split()))
# 上昇に転じた時に買いたいのでDから始める
trend = 'D'
for i in range(1, n):
now = al[i]
prev = al[i - 1]
if now <= prev:
trend += 'D'
else:
trend += 'U'
rle = run_length_encode(trend)
cap = 1000
idx = 0
stack = []
for char, cnt in rle:
idx += cnt
if char == 'D':
stack.append(idx)
else:
peak = stack.pop()
# 一回株を変えるだけ買う
buy_price = al[peak - 1]
holding = cap // buy_price
cap %= buy_price
# 株を全部売る
sell_price = al[idx - 1]
cap += sell_price * holding
print(cap)
job()
似たような問題でARCにはこんなのがありました。
こちらは最初に金を1g持っていて、数列が条件として与えられます。
そのような中で以下の条件で取引を行います。
Xグラムの金を持っていたなら、全て銀に交換し、X×A_iグラムの銀を得る
Xグラムの銀を持っていたなら、全て金に交換し、X/A_iグラムの金を得る
最終的に金の所持量を最大にする場合、いつに取引をするのが最適か、ということを出力する問題です。
考察をすると、以下のように取引すると良いです。
- 銀を一番入手できるときに、金を銀に交換する。
- 金を一番入手できるときに、銀を金に交換する。
先ほどとは逆で、上げ基調の頂点で金を打って銀を買う、下げ基調の底で銀を打って金を入手します。
空売りっぽい感じですね。
from itertools import groupby
def run_length_encode(s: str) -> list:
"""
RUN LENGTH ENCODING str -> list(tuple(str,int))
example) "aabbbbaaca" -> [('a', 2), ('b', 4), ('a', 2), ('c', 1), ('a', 1)]
"""
grouped = groupby(s)
ret = []
for k, v in grouped:
elm = (k, len(list(v)))
ret.append(elm)
return ret
def job():
n = int(input())
al = list(map(int, input().split()))
# 最初頂点で銀に変えたいので、Uから始める
trend = 'U'
for i in range(1, n):
if al[i] >= al[i - 1]:
trend += 'U'
else:
trend += 'D'
rle = run_length_encode(trend)
stack = []
idx = 0
ans = [0] * n
for elm in rle:
char, cnt = elm
idx += cnt
if char == 'U':
stack.append(idx)
else:
if stack:
ans[idx - 1] = 1
peak = stack.pop()
ans[peak - 1] = 1
stack = []
print(*ans)
job()
おわりに
計算量は多少増えるのですが、あまり頭を使わずに機械的に頂点と底を確認できて楽だと感じました。
引き出しの一つとして持っておいて、損はないでしょう。ではでは。
 Share
Share